
生成式 AI - 讓 AI 讀懂你的資料:檢索增強生成 (RAG)
ChatGPT 很強,但它會胡說八道,而且不知道你公司的機密。本篇將介紹當今企業最熱門的 AI 技術:RAG (檢索增強生成),並透過 Python 帶你親手打造一個 Mini RAG 系統!
WRITTEN BY

- Name
- Harry Chang
我們從最基礎的線性回歸,一路學到了深度學習、Transformer、強化學習,最後解開了 XAI 黑盒子。 今天,我們終於要踏入當今業界最熱門、幾乎所有企業都在瘋搶導入的技術領域:RAG (Retrieval-Augmented Generation,檢索增強生成)。
1. 為什麼我們需要 RAG?
大語言模型 (LLM, 像是 ChatGPT) 雖然非常強大,但它們在企業應用上有兩個致命傷:
- 幻覺 (Hallucination):當它不知道答案時,很容易一本正經地胡說八道。
- 知識斷層 (Knowledge Cutoff):它只知道訓練資料截止日以前的公開資訊,完全不知道「你公司昨天的會議記錄」或是「你家的貓叫什麼名字」。
RAG 的終極解法
在叫 AI 回答問題之前,先去你的 「私有資料庫」 翻書,把最相關的資料找出來,然後把資料跟問題一起塞給 AI 參考。
💡 兩種訓練 AI 方式的比喻:
- Fine-tuning (微調):就像是送 AI 去補習班,把新知識死「背」進腦袋裡。(成本極高、訓練極慢、一旦知識更新又要重背一次)
- RAG (檢索增強):就像是給 AI 一本「教科書」,讓它考試時可以 Open Book (開卷考試)。(成本超低、速度極快、隨時可以抽換教科書更新知識)
2. RAG 運作流程 (The Pipeline)
一個標準的 RAG 系統可以拆解成三個關鍵步驟:
- 建立知識庫 (Indexing):
- 切塊 (Chunking):把長達萬字的文章切成一小段一小段。
- 向量化 (Embedding):利用神經網路把每一小段文字變成「數學向量 (Numbers)」,存入特別設計的 向量資料庫 (Vector DB)。
- 檢索 (Retrieval):
- 當使用者提問:「公司的請假規定是什麼?」
- 系統會把這個「問題」也轉成向量,然後去資料庫找出**「長得最像」**(在多維空間中距離最近) 的幾個段落。
- 生成 (Generation):
- 把「找到的規定段落」+「使用者的問題」打包組合成一個超大的 Prompt。
- 丟給 LLM,讓它根據你給的參考資料,生成一段語意通順的最終答案。
RAG 核心架構圖
這張圖清晰展示了 RAG 如何讓原本一無所知的 AI 變得「有腦袋」:
🔍 圖解說明:
- 右邊建檔 (Knowledge Base):我們先把私有資料 (貓的名字) 轉成向量存起來。
- 左邊提問 (User):使用者問問題,系統把問題也轉成向量。
- 中間檢索 (Search):用向量比對技術,找出與問題最相關的歷史資料 (Context)。
- 下方生成 (LLM):把「問題」和「找到的參考答案」一起餵給 LLM,讓它用漂亮的人話講出來。
3. 實戰:打造一個 Mini RAG
為了徹底理解原理,我們不依賴龐大的框架 (如 LangChain),直接用 Python 從頭手刻一個最原汁原味的 RAG 系統!
3.1 程式碼架構 (RAG_Demo.py)
- 資料準備:我們準備一些關於 "30-Days-Of-ML" 的虛構私有資料 (為了配合輕量級的開源模型,這裡使用英文展示)。
documents = [ "30-Days-Of-ML is a machine learning challenge initiated by Harry.", "In Day 37, we learned the DQN algorithm to play the CartPole game.", "The topic of Day 39 was XAI (Explainable AI), using the SHAP library.", "Harry's cat is named 'Oreo', and it loves sleeping on the keyboard.", "The ultimate goal of this project is to build a RAG system." ] - Embedding 模型:使用
sentence-transformers(如all-MiniLM-L6-v2) 來將文字精準轉成多維度的數學向量。 - 向量搜尋:使用
numpy計算 餘弦相似度 (Cosine Similarity),幫我們在上百筆資料中瞬間找出最相關的句子。 - 生成回答:使用
transformers(GPT-2) 根據找到的資料作為 Context 來回答使用者的問題。
4. 執行結果與解讀
執行這支手刻的 Python 程式後,你會看到類似以下的精彩輸出:
檢索成功 (Retrieval Works!)
當我們向系統提問 "What is the name of Harry's cat?" 時:
【檢索到的相關資料】 :
1. Harry's cat is named 'Oreo', and it loves sleeping on the keyboard. (相似度: 0.8234)
- 分析:系統利用向量相似度,成功且精準地從知識庫中把包含 "Oreo" 的這條獨家資訊給撈出來了!
生成結果 (Generation)
Question: What is the name of Harry's cat?
Answer: Oreo
- 分析:雖然 GPT-2 本身非常古老,也完全不知道 Harry 是誰。但透過 RAG,我們在考前硬是塞給了它「參考資料 (Context)」,它就能瞬間看懂並正確回答出 "Oreo"!
- 這就是 RAG 的最大威力:賦予 AI 無窮無盡且隨時可更新的外部大腦。
邁向企業級:Production RAG 架構
上面我們示範了最核心的原理,但真實業界的情況會複雜許多。 這是我近期參加 AI 應用規劃師課程中,針對「企業專利文件知識庫」所設計的 RAG 企業級解決方案架構圖。底層基於 LangChain,並透過網頁介面讓使用者進行流暢的對話:
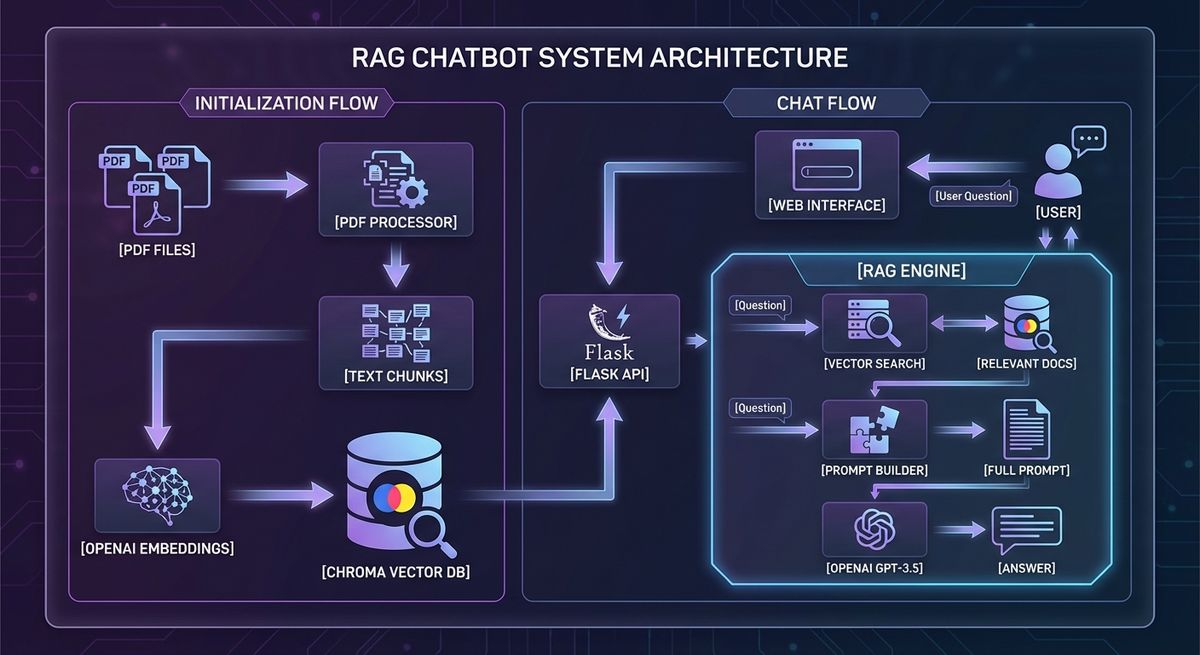
(企業級 RAG 系統架構圖)
架構深度解讀
- Document Loaders (左上):負責讀取企業內部千奇百怪的格式 (PDF, Word, HTML, Excel)。
- Text Splitters (左下):把長篇大論切成最適合 AI 吞嚥的小塊 (Chunking),這往往是決定 RAG 準確率最吃重的一環。
- Vector Store (中間):揚棄簡單的 Array,改用企業級的專業向量資料庫 (如 ChromaDB, Pinecone, Qdrant) 來確保百萬筆資料的檢索速度。
- Retriever (右上):除了基本的「相似度搜尋」,通常還會掛載「關鍵字搜尋 (Hybrid Search)」或導入「重排序 (Re-ranking)」機制,確保撈出來的資料是最關鍵的。
- LLM (右下):萬事俱備後,最後才交給最強大的 LLM (如 GPT-4o 或 Claude 3) 來負責閱讀與生成完美答案。
5. 總結
RAG 絕對是當今企業導入 AI 最具性價比、也是最重要的落地技術。 它完美解決了幻覺與資料隱私的問題,讓 AI 真正成為企業內部的超級員工。
Day 28 我們將回頭補齊電腦視覺的最後一塊拼圖:YOLO 物件偵測! 我們不僅會教你怎麼讓 AI 「看懂」圖片,更要讓它能精準「定位」出所有物件。大家準備好接受挑戰了嗎?