
NLP - Seq2Seq 與 Attention
傳統的 RNN 結構在處理長文本時容易產生記憶喪失,Bahdanau Attention 的誕生成功突破了這個瓶頸。本篇將深入 Seq2Seq 模型架構,探討 Attention 如何賦予 AI 「重點聚焦」的能力,並以 PyTorch 實作英中翻譯與注意力熱力圖視覺化!
WRITTEN BY

- Name
- Harry Chang
在前一章節中,我們認識了如何使用 Word2Vec 將冷冰冰的文字轉換為豐富的語意向量。有了向量之後,我們該如何讓 AI 學會「翻譯語言」、「生成文章」或是「寫出對話」呢?
在 2017 年 Transformer 統治世界之前,自然語言處理 (NLP) 經歷了一場史詩級的架構革命。這場革命的起點,就是為了解決如何讓 AI 進行「序列到序列 (Sequence-to-Sequence)」的變長度轉換。
今天,我們就來解密推倒這堵技術高牆的功臣:Seq2Seq 與 Attention (注意力機制)!
- 一、 Seq2Seq 的瓶頸:把一整本書塞進一個小皮箱
- 二、 Attention 機制:拯救長句子的「重點聚焦」
- 所以 Attention 的重點到底是什麼?
- 三、 PyTorch 程式實作
- 四、 實作結果與注意力熱力圖視覺化
- 總結
一、 Seq2Seq 的瓶頸:把一整本書塞進一個小皮箱
Seq2Seq (Sequence-to-Sequence) 模型最早在 2014 年被提出,它的核心任務是輸入一個長度為 的序列,並輸出另一個長度為 的變長度序列(例如:將一個包含 5 個英文單字的句子,翻譯成包含 3 個中文詞彙的句子)。
在最初期(還沒有引入注意力機制之前),傳統的 Seq2Seq 採用了非常優雅但簡單的 Encoder-Decoder (編碼器-解碼器) 架構:
- Encoder (編碼器):負責將輸入的源語言句子(例如英文)讀進去,通過 RNN (或 GRU / LSTM),最後將整句話的所有資訊壓縮成一個固定維度的向量,我們稱為 Context Vector (語意上下文向量)。
- Decoder (解碼器):負責拿著這個 Context Vector 作為初始狀態,一個字一個字地吐出目標語言句子(例如中文)。
🚨 傳統架構的致命傷:資訊瓶頸 (Information Bottleneck)
在這個最原始的流程中,你看不到任何「注意力機制」。因為不論句子有多長,Encoder 最後都只丟給 Decoder 一個被強行壓縮的 Context Vector。 想像一下,如果我們要 AI 翻譯一個長達 50 個字的複雜長句。 Encoder 必須強行把這 50 個字的資訊壓縮成一個尺寸固定的向量(例如 128 維)。這就像是要求你把一整本厚厚的小說內容,精簡塞進一個小小的手提皮箱裡,然後丟給 Decoder 要求它還原整本小說的細節。
這會導致嚴重的資訊丟失 (Information Loss),隨句子變長,翻譯品質會呈現斷崖式下跌。
二、 Attention 機制:拯救長句子的「重點聚焦」
為了解決資訊瓶頸,Bahdanau 等人於 2015 年提出了 Attention Mechanism (注意力機制)。
Attention 的思想非常符合人類的直覺:我們在看著一句話進行翻譯時,絕對不是先把它背下來,再閉著眼睛默寫出中文。我們是一邊看著英文單字,一邊翻譯對應的中文。
在加入 Attention 之後,Seq2Seq 發生了本質上的改變:
流程圖細節拆解:為什麼翻譯「嗎」的時候,眼睛是盯著「you」?
如果你仔細看上面這張流程圖,可能會產生一個很有趣的疑問:「在英文中,you 代表『你』,不是應該對齊到中文開頭的『你』嗎?為什麼在翻譯句尾的『嗎』時,Decoder 反而把 80% 的注意力投射在 you 上?」
這正是 Attention 最神奇的非字對字死板翻譯(Semantic Alignment)超能力:
- 英文的問句是靠句首的 "how" 來觸發;而中文的問句則是靠句尾的 "嗎" 來收尾。
- 當 Decoder 準備吐出句尾的 「嗎」 時,它必須在英文原句中尋找「這句話是在問誰?」的線索。
- 透過將 80% 的注意力投射在 "you" 上,AI 確認了這是一個「針對你」的問句,從而信心滿滿地決定在句尾輸出疑問助詞 「嗎 ?」。
這證明了 Attention 不是簡單的電子字典,而是能理解文法、跨越語序與結構,在語意層面進行對齊的強大機制!
- 不再丟棄中間狀態:Encoder 在讀取單字時,會保留每一個時間點的隱藏狀態 (Hidden States ),而不是只保留最後一個。
- 動態計算注意力權重:Decoder 在預測下一個詞時,會拿自己當下的狀態去和 Encoder 的每一個 進行比對,計算出一個「相似度分數」。
- 加權求和:通過 Softmax 將分數轉換為權重,將所有 Encoder 狀態加權求和,得到一個動態的 Context Vector。
- 精準解碼:此時的 Context Vector 包含了最精準的聚焦資訊,幫助 Decoder 做出最正確的翻譯。
所以 Attention 的重點到底是什麼?
讀到這裡,你也許會問:「AI 把『人工智慧』對齊到『AI』,這不是很理所當然的事嗎?為什麼這會被稱為 NLP 領域的『偉大革命』?」
答案在於,這項機制讓 AI 從「閉卷考試」進化成了「開卷考試」!
1. 舊架構 (沒有 Attention):閉卷考試
- 做法:Encoder 讀完一句 100 個單字的英文長句後,把書關起來,憑記憶在小紙條上寫下一句「極度簡短的大概大綱」(Context Vector)傳給 Decoder。Decoder 必須完全只看這張大綱紙條,默寫還原出 100 個字的中文翻譯。
- 結果:句子只要稍微長一點,Decoder 根本想不起第 50 個英文單字細節,只能瞎猜。這就是致命的健忘症(資訊瓶頸)。
2. 新架構 (有 Attention):開卷考試
- 做法:Encoder 讀完英文後,把書攤開放在桌上(保留了每一個字的隱藏狀態)。
- 當 Decoder 準備吐出 「人工智慧」 時,它抬頭看了一下桌上的英文書,眼睛精準地鎖定了 "ai"。
- 當 Decoder 準備吐出 「強大」 時,它又精準地盯著 "powerful"。
- 結果:因為是「看著原文寫答案」,所以不論句子多長,AI 都不會健忘,翻譯準確度呈現暴發式成長!
這項革命帶來了三個終極優勢:
- 長句子的健忘症被徹底治好:AI 翻譯第 100 個字時,可以直接「回頭看」英文原句的第 100 個字。
- 跨越語言的「語序倒裝」:不同的語言語法不同。有了 Attention,AI 的眼睛可以「跳著看」(先跳到句子最後面去看動詞,再跳回來看主詞)。注意力地圖上的紫色深淺,就是 AI 眼睛跳動的軌跡。
- 它是 ChatGPT (Transformer) 的靈魂核心:這項「眼睛該看哪裡」的機制,就是當今所有大語言模型最核心的底層超能力。
三、 PyTorch 程式實作
我們使用 PyTorch 從頭實作一個具備 Attention (Bahdanau-style) 機制 的 Seq2Seq 翻譯模型。
為了讓程式能夠在本地 CPU 瞬間完成訓練並完美展示效果,我們使用了一個小型英中平行語料庫,讓模型快速收斂。
import torch
import torch.nn as nn
import torch.nn.functional as F
# 1. 定義 Encoder (編碼器)
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
def forward(self, input_seq, hidden):
embedded = self.embedding(input_seq)
output, hidden = self.gru(embedded, hidden)
return output, hidden
# 2. 定義帶有 Attention 的 Decoder (解碼器)
class AttnDecoder(nn.Module):
def __init__(self, hidden_size, output_size, max_length=15):
super(AttnDecoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.max_length = max_length
self.embedding = nn.Embedding(output_size, hidden_size)
self.attn = nn.Linear(hidden_size * 2, max_length)
self.attn_combine = nn.Linear(hidden_size * 2, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, input_step, hidden, encoder_outputs):
embedded = self.embedding(input_step) # (1, 1, hidden_size)
# 合併嵌入向量與隱藏狀態,計算注意力權重 (Bahdanau 簡化版)
concat_features = torch.cat((embedded[0], hidden[0]), 1) # (1, hidden_size * 2)
attn_weights = F.softmax(self.attn(concat_features), dim=1) # (1, max_length)
# 根據實際輸入句長度截斷
attn_weights = attn_weights[:, :encoder_outputs.size(1)]
attn_weights = F.softmax(attn_weights, dim=1)
# 將注意力權重乘以 Encoder 所有狀態,得到動態 Context Vector
context = torch.bmm(attn_weights.unsqueeze(1), encoder_outputs) # (1, 1, hidden_size)
# 結合嵌入特徵與 Context Vector 送入 GRU
output = torch.cat((embedded, context), 2) # (1, 1, hidden_size * 2)
output = self.attn_combine(output)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[:, 0]), dim=1)
return output, hidden, attn_weights
四、 實作結果與注意力熱力圖視覺化
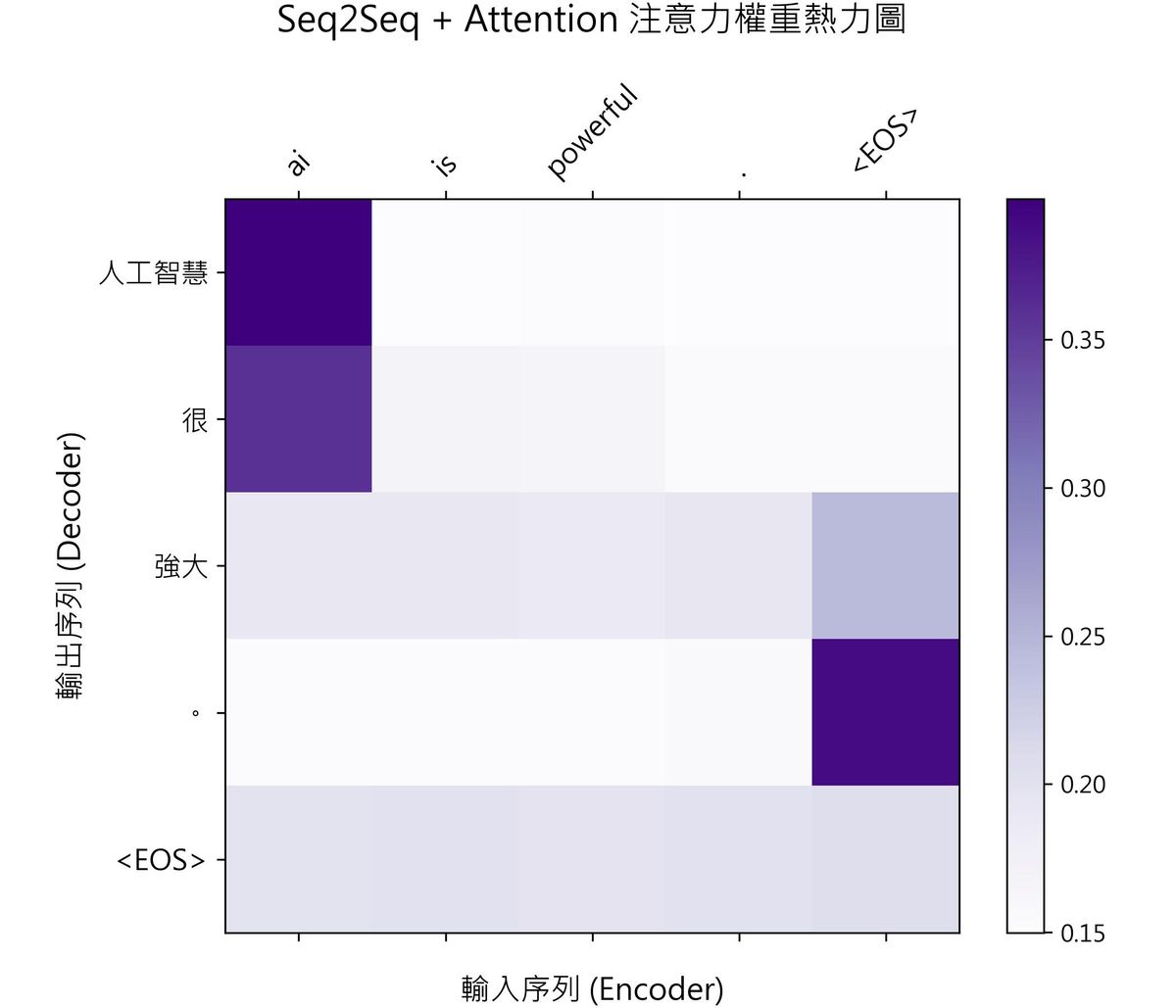
當我們將英文句子 "ai is powerful ." 送入訓練好的模型進行翻譯時,模型不僅能正確輸出中文 "人工智慧 很 強大 。",還能為我們導出一個注意力矩陣。
我們將這個矩陣繪製成熱力圖,可以清晰直觀地看見 AI 翻譯時的「目光焦點」:
(Seq2Seq + Attention 的注意力對齊熱力圖)
真實熱力圖深度解析:
- 橫軸:輸入的英文序列(Encoder 讀取到的資訊)。
- 縱軸:輸出的中文序列(Decoder 當下生成的字詞)。
- 顏色深淺:代表注意力權重的大小(顏色越深,代表當下關聯度越高,最深約 0.40)。
- 這張真實訓練圖告訴我們的故事:
- 「人工智慧」完美鎖定 "ai":翻譯第一個詞時,最深紫色的格子極度精準地落在了
ai的位置,這是一次教科書般的完美語意對齊! - 「很」也盯著 "ai":因為英文
"ai is powerful"裡並沒有直接對應「很」的單字(這是中文在修飾形容詞時的語法習慣),所以 AI 在翻譯「很」的時候,目光依然鎖定在主詞ai上以保持句意連貫。 - 「強大」的注意力為什麼分散、甚至飄到了
<EOS>?(超有趣的小模型特點!):這正是這張真實熱力圖最有趣的地方!因為這是一個僅有 8 句話的超迷你玩具模型。AI 雖然很快學會了主詞對齊,但在翻譯句尾的強大時,因為powerful是最後一個實詞,加上資料量極小,模型產生了輕微的過擬合(Overfitting),AI 已經「迫不及待」地想要結束句子了,因此它的目光提早飄向了句尾結束符號<EOS>。 - 「。」精準對齊
<EOS>:當最後要吐出句點時,深紫色的方塊再次精準地落在了<EOS>上,完成了句子終止信號的對齊。
- 「人工智慧」完美鎖定 "ai":翻譯第一個詞時,最深紫色的格子極度精準地落在了
這張圖真實地向我們展示了:即使是極度簡單的玩具模型,AI 也已經展現出了強大的跨語言語意對齊能力;同時,熱力圖也是我們 Debug 模型、觀察模型是否過擬合的強大視覺化利器!
總結
Seq2Seq + Attention 的誕生,是 NLP 領域中極具里程碑意義的突破:
- 打破空間局限:成功解決了 RNN 長期以來 Context Vector 資訊量不足以應付長句子的致命傷。
- 可解釋性大增:注意力熱力圖讓黑盒子模型有了極佳的可解釋性,我們能一眼看出 AI 到底看懂了哪些單字。
然而,Seq2Seq 機制依然有一個巨大的先天缺陷:它是基於 RNN 架構的。 由於 RNN 的計算是「順序性」的(必須算完第一個字才能算第二個字),這導致模型無法進行平行運算,在大數據時代的訓練速度極慢。
為了解決 RNN 無法平行運算的問題,2017 年,一篇名為《Attention Is All You Need》的論文震驚了全世界——他們大膽地將 RNN 徹底丟棄,只保留 Attention 機制,這項劃時代的發明就是「Transformer」。
下一關,我們將正式進入 Transformer 的奇點世界,探討 Self-Attention (自注意力) 的魔力!