
不平衡資料處理:SMOTE 與 Focal Loss - 職災稀有事件預測
職災預測最大的敵人不是模型不夠強,而是資料天生不平衡:97% 準確率的模型可能漏掉四分之三的事故。本篇介紹兩大對策——資料層的 SMOTE 合成採樣與損失函數層的 Focal Loss,並用實驗揭露一個反直覺的真相:它們改變的往往不是模型的能力,而是決策的立場。
WRITTEN BY

- Name
- Harry Chang
核心貢獻者
Nitesh V. Chawla (聖母大學) 於 2002 年提出 SMOTE (Synthetic Minority Over-sampling Technique),這篇論文是機器學習史上引用數最高的論文之一 (超過 3 萬次)——因為「類別不平衡」是每個實務工作者遲早撞上的牆。Tsung-Yi Lin 與 Kaiming He (何愷明) 等人則在 2017 年的 RetinaNet 論文中提出 Focal Loss,為了解決物件偵測中前景/背景高達 1:1000 的極端不平衡,拿下 ICCV 最佳學生論文獎。
為什麼工安資料天生不平衡?
上一篇 (Day 40) 我們用非監督方法在「沒有標籤」時抓異常。這一篇處理另一種情境:你有標籤,但標籤慘不忍睹地偏斜。
一間管理良好的工廠,每 100 個班次可能只有 2~3 個班次出現虛驚事件或輕微事故。這就是「職災是稀有事件」的資料現實:正常 : 事故 ≈ 97 : 3。而它會製造一個惡名昭彰的陷阱——
準確率悖論 (Accuracy Paradox)
一個「無論如何都預測不會出事」的懶惰模型,準確率直接就有 97%。聽起來很棒,但它的 Recall 是 0%:一件事故都抓不到。在不平衡資料上,準確率是最會說謊的指標——這也是 Day 02 混淆矩陣的進階應用場景。
1. 資料集來源
資料集:合成班次職災風險資料
備註:延續 Day 40 的做法,用 NumPy 模擬並埋入已知的風險結構,才能對答案驗證各種對策的效果。
資料集特色與欄位介紹:
模擬 5,000 筆班次紀錄,事故率 2.94% (147 筆)——訓練集裡少數類只有 103 筆,對上 3,397 筆正常班次。
欄位說明:
- overtime (月加班時數):越高風險越高。
- experience (經驗月數):越資深風險越低。
- consec_days (連續工作天數):疲勞累積的主因。
- maint (距上次保養天數):設備劣化風險。
- noise (環境噪音 dB):注意力干擾。
風險結構:事故機率由這五個因子的邏輯斯模型生成,再加上隨機性——和真實世界一樣,高風險班次不一定出事,低風險班次也可能倒楣,兩類在特徵空間大量重疊。
資料清理
- 標準化:邏輯回歸與神經網路都需要。
- 分層抽樣 (stratify):切訓練/測試集時務必用
stratify=y,否則 3% 的少數類可能在測試集裡只剩個位數,指標會抖到不能看。
2. 原理
面對不平衡,對策分成三層:資料層 (SMOTE)、損失函數層 (class weight / Focal Loss)、決策層 (閾值移動)。
2.1 資料層:SMOTE——不是複製,是「內插合成」
最直覺的做法是把少數類複製貼上 (Random Over-sampling),但完全相同的樣本會讓模型死背。SMOTE 聰明一點:在少數類樣本和它的 k 個少數類鄰居之間的連線上,隨機取點合成新樣本。
- :某個少數類樣本;:它的 k 近鄰之一 (預設 k=5);:0 到 1 的隨機數。
- 直覺:在「事故案例」和「相似的事故案例」之間畫線,線上的點大概也長得像事故。
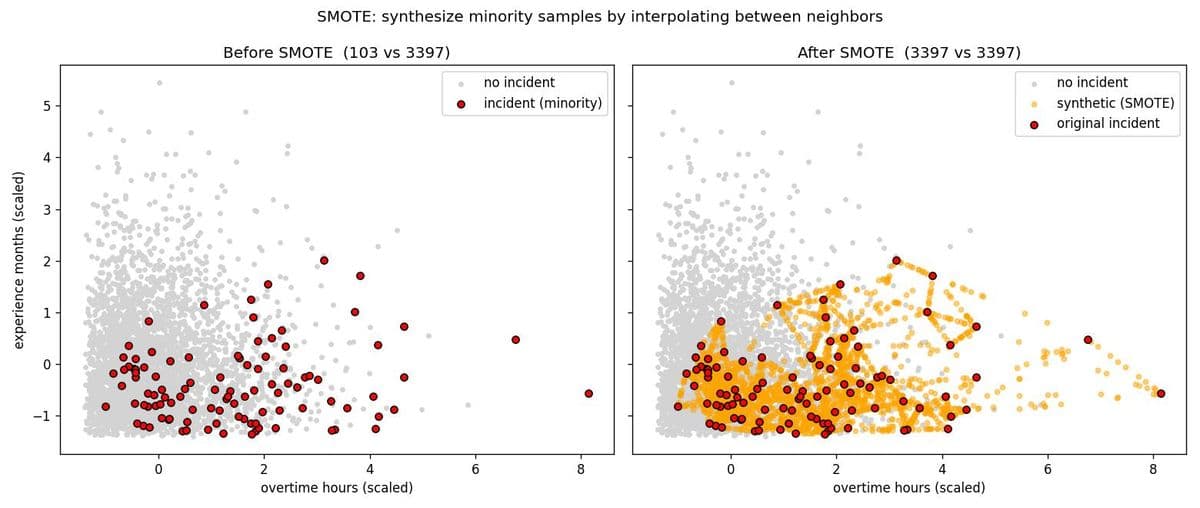
右圖橘色點就是合成樣本——可以清楚看到它們沿著紅點之間的連線生長,把 103 筆事故撐成 3,397 筆,和多數類 1:1 平衡。
兩個致命注意事項:
- 只能對訓練集做! 若在切分前做 SMOTE,合成樣本的「父母」可能一個在訓練集、一個在測試集——這是資料洩漏 (Data Leakage),測試成績會虛胖。
- 測試集永遠保持原始分布:你要評估的是模型在真實世界 (97:3) 的表現,不是在人造世界 (50:50) 的表現。
2.2 損失函數層 (一):Class Weight——出一次事,罰一百倍
不動資料,改動懲罰:把少數類的錯誤在損失函數中乘上更大的權重。class_weight='balanced' 會自動設成類別頻率的倒數——事故只佔 3%,答錯一筆事故的痛就放大約 33 倍。這招又叫成本敏感學習 (Cost-Sensitive Learning),而它在工安場景有完美的對應:漏報一場事故的成本,本來就遠大於誤報一次的成本。
2.3 損失函數層 (二):Focal Loss——把火力集中在難題上
Class weight 只按「類別」加權,Focal Loss 更細:按「難度」加權。
- :模型對正確類別給出的機率。 接近 1 代表這題模型答得很有把握 (簡單題)。
- :調變因子,整個公式的靈魂。簡單題的 趨近 0,損失被打折到幾乎消失;難題保留完整損失。
- (gamma):打折的力度,設 0 時退化回一般的交叉熵;論文建議 2。
- :順手做類別加權 (類似 class weight)。
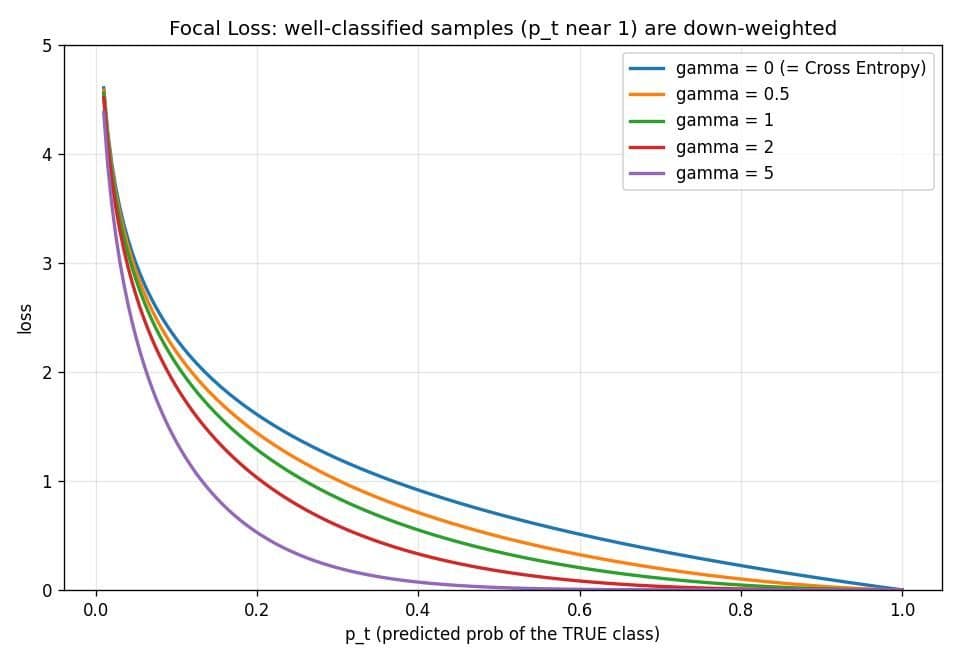
- 直覺:不平衡資料中,海量的「簡單多數類」會用蚊子般的小損失淹沒訓練訊號。Focal Loss 把這群蚊子拍掉,讓梯度集中在少數類與邊界上的難例。
- 出身:它為 RetinaNet 的單階段物件偵測而生 (Day 28 YOLO 的同賽道),那裡的背景框:前景框可達 1000:1——比職災資料更極端。
2.4 決策層:閾值移動——最便宜卻最常被遺忘的一招
模型輸出的是機率,預設用 0.5 切成是/否。但誰說一定要 0.5?把閾值降到 0.2,等於宣告「兩成風險我就要查」——不改資料、不改模型,只改決策立場。這招的價值在看完實驗結果後會更有感。
3. 實戰
Python 程式碼實作
from imblearn.over_sampling import SMOTE
from sklearn.linear_model import LogisticRegression
import torch.nn.functional as F
# ---- 對策一:class_weight(一行搞定)----
lr_w = LogisticRegression(class_weight='balanced').fit(X_train_s, y_train)
# ---- 對策二:SMOTE(只對訓練集!)----
X_res, y_res = SMOTE(random_state=42).fit_resample(X_train_s, y_train)
print(np.bincount(y_res)) # [3397 3397] 已平衡
lr_sm = LogisticRegression().fit(X_res, y_res)
# ---- 對策三:Focal Loss(自訂損失函數,搭配小型 MLP)----
def focal_loss(logits, targets, alpha=0.9, gamma=2.0):
bce = F.binary_cross_entropy_with_logits(logits, targets, reduction='none')
p_t = torch.exp(-bce) # 對正確類別的預測機率
alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
return (alpha_t * (1 - p_t) ** gamma * bce).mean()
程式碼重點:
- SMOTE 來自
imbalanced-learn套件 (sklearn 的姊妹專案),API 與 sklearn 完全同款。 - Focal Loss 的實作技巧:
p_t = exp(-BCE)是個優雅的小把戲——因為 ,取負再取指數就還原出 。
4. 模型評估
四種策略在「原始分布測試集」上的對決
| 策略 | Accuracy | Precision | Recall | F1 | PR-AUC |
|---|---|---|---|---|---|
| Baseline LR | 0.9747 | 0.6875 | 0.2500 | 0.3667 | 0.5560 |
| Weighted LR | 0.8387 | 0.1464 | 0.9318 | 0.2531 | 0.5689 |
| SMOTE + LR | 0.8467 | 0.1504 | 0.9091 | 0.2581 | 0.5591 |
| Focal Loss MLP | 0.9293 | 0.2373 | 0.6364 | 0.3457 | 0.4119 |
- 準確率悖論現場直播:Baseline 準確率 97.47% 最高,但 Recall 只有 25%——測試集 44 件事故它漏掉 33 件。如果職安主管只看準確率採購系統,買到的就是這種「安靜的幫兇」。
- Weighted 與 SMOTE:Recall 飆到九成以上 (44 件抓到 41 件),代價是 Precision 掉到 15%——每 7 次告警只有 1 次是真的。用誤報換漏報,這正是工安場景想要的交易方向。
- Focal Loss:站在中間,Recall 64%、Precision 24%,F1 反而接近 Baseline。
本篇最重要的一張圖:PR 曲線揭露的真相
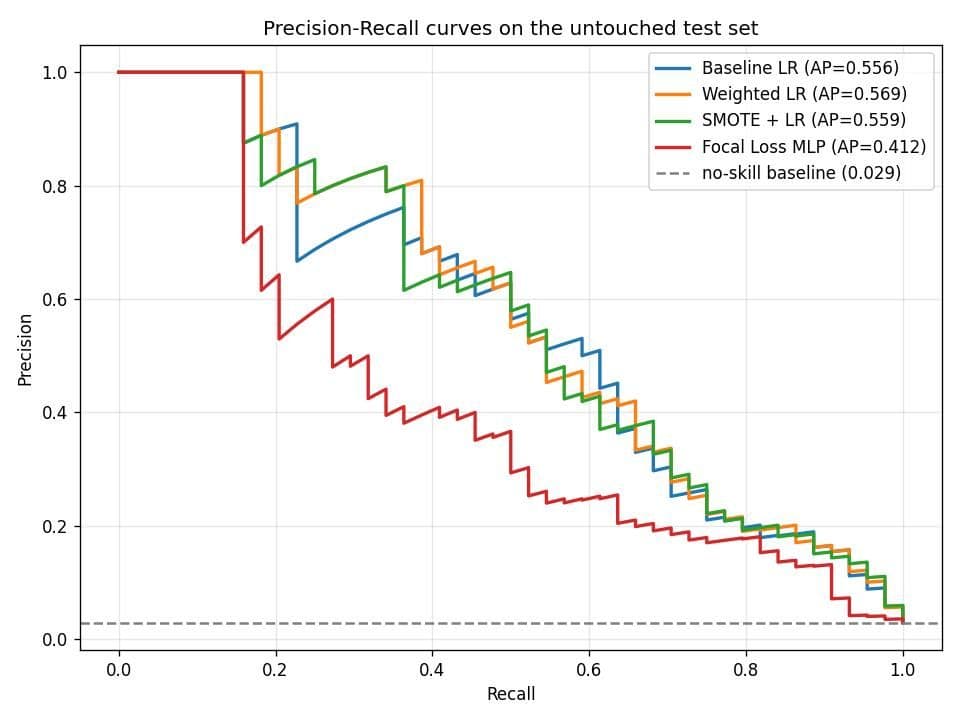
看出來了嗎?Baseline、Weighted、SMOTE 三條曲線幾乎完全重疊 (AP 0.556 / 0.569 / 0.559)。
- 這代表:對邏輯回歸這種線性模型,加權和 SMOTE 幾乎沒有提升模型「把高風險排在前面」的排序能力——它們做的,本質上只是把決策邊界往少數類那邊推,讓預設 0.5 閾值落在不同的工作點上。
- 換句話說:Baseline 模型直接把閾值降到 0.15,效果就和大費周章做 SMOTE 差不多。這就是 2.4 節說「閾值移動最便宜」的原因——先畫 PR 曲線、按業務成本選工作點,常常就夠了。
- 那 SMOTE/Focal Loss 什麼時候真有用?當模型是非線性的 (樹模型、神經網路) 且少數類結構複雜時,重採樣與難例加權才會真正改變模型學到的邊界形狀,而不只是平移它。
- 工安視角的收尾:指標的取捨不是數學問題,是管理問題——「每天多查 6 次誤報」換「一年少漏 30 件事故前兆」,這筆帳職安室算得出來,模型算不出來。
5. 總結
我們學習了不平衡資料的三層對策:
- SMOTE:在少數類鄰居連線上內插合成新樣本;切記只對訓練集做,測試集保持原始分布。
- Class Weight / Focal Loss:前者按類別加重懲罰,後者按難度動態打折——把訓練火力從海量簡單題轉向關鍵難例。
- 閾值移動:最便宜的一招。PR 曲線實驗揭露:對線性模型,重採樣與加權往往只是「移動工作點」,先調閾值再談重武器。
- 工安啟示:97% 準確率可能是一個一件事故都抓不到的模型。評估稀有事件模型,永遠先看 Recall 與 PR 曲線,再讓管理層用成本決定工作點。
下一篇進入時序領域:工傷件數有淡旺季嗎?設備故障有週期嗎?ARIMA 與 Prophet 教模型看懂時間的節奏。