
—
模型優化策略-合成正弦波數據為例
為什麼模型在訓練時表現完美,上線後卻一塌糊塗?本篇透過經典的「正則波」實驗,帶你直觀理解偏差 (Bias) 與方差 (Variance) 的博弈,學會如何抓出「只會死背」的過擬合模型。
在 ML002 中,我們學會了如何透過指標衡量模型。但當我們發現模型表現不佳時,通常會面臨兩個極端:模型太笨(Underfitting),或是模型太聰明卻鑽牛角尖(Overfitting)。
今天我們透過 合成正弦波數據 (Synthetic Sinusoidal Data),在實驗室環境下解剖這兩個機器學習的頭號大敵。
- 一、 實驗設計:模擬真實世界的雜訊
- 二、 擬合的三種境界:從太笨到太聰明
- 三、 核心理論:偏差 (Bias) vs 方差 (Variance) 的博弈
- 四、 欠擬合 (Underfitting):模型「學不夠」怎麼辦?
- 五、 過擬合 (Overfitting):模型「想太多」怎麼辦?
- 六、 本日總結:如何找到 Sweet Spot?
一、 實驗設計:模擬真實世界的雜訊
為了看清模型的本質,我們人造了一個正弦波訊號,並加入了一些隨機雜訊。
資料欄位說明:
在這個實驗中,我們只有兩個核心維度:
- X (特徵):輸入變數,範圍在 到 之間(例如:實驗的觀察點)。
- y (目標):我們觀測到的數值,這也是模型要預測的結果。
此外,為了驗證模型的準確性,我們定義了:
- 真實函數 (True Function):數據背後的「真理」(藍色虛線),公式為 。
- 雜訊 (Noise):隨機加入的擾動( 的誤差),模擬現實中的測量誤差。
我們的目標是:透過這 30 個帶雜訊的點 (X, y),還原出背後的藍色虛線。
二、 擬合的三種境界:從太笨到太聰明
我們使用了三種不同複雜度的多項式模型來進行測試:
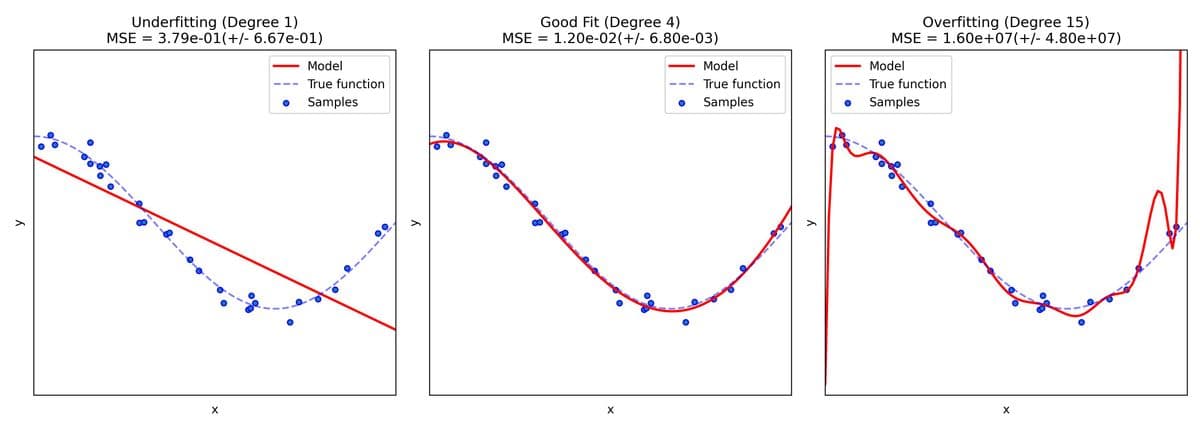
1. 欠擬合 (Underfitting):高偏差 (High Bias)
- 表現 (左圖):模型用一條直線去猜曲線。
- 診斷:模型太過簡單,完全無法捕捉數據的趨勢。
- 後果:訓練集和測試集的表現都很差。這就像是「書讀得太少」,連基本規律都沒掌握。
2. 剛好擬合 (Good Fit):完美的平衡
- 表現 (中圖):模型優雅地穿過點陣,完美還原了原始曲線。
- 診斷:模型複雜度適中,成功區分了「規律」與「雜訊」。
- 後果:這就是我們追求的 Sweet Spot。
3. 過擬合 (Overfitting):高方差 (High Variance)
- 表現 (右圖):模型為了貼近每一個點,產生了劇烈的震盪。
- 診斷:模型太過複雜,它把「雜訊」當成了「規律」來死背。
- 後果:訓練集表現趨於完美,但測試集(MSE 暴增)一塌糊塗。這就是典型的「書讀死,不會變通」。
三、 核心理論:偏差 (Bias) vs 方差 (Variance) 的博弈
這是機器學習的核心矛盾,決定了模型的生死:
| 特性 | 偏差 (Bias) | 方差 (Variance) |
|---|---|---|
| 定義 | 模型預測值與真實值之間的距離。 | 模型在不同資料集上的穩定度。 |
| 高值表現 | 欠擬合 (Underfitting) | 過擬合 (Overfitting) |
| 錯誤來源 | 對數據的假設太簡單(如用直線猜曲線)。 | 對數據的變動太敏感(死背雜訊)。 |
| 解決方案 | 增加特徵、使用更複雜的模型。 | 正則化 (L1/L2)、增加數據、減少特徵。 |
四、 欠擬合 (Underfitting):模型「學不夠」怎麼辦?
當模型過於簡單,無法捕捉到數據中的真實規律時,就會發生欠擬合。這就像是一個「書讀太少」的學生。
| 任務類型 | Underfitting 的表現 (症狀) | 核心對抗策略 (加餐藥方) |
|---|---|---|
| 回歸 (Regression) | R2 低、誤差大。無法捕捉趨勢(如用直線猜正弦波)。 | 增加特徵、提升多項式次數、減少正則化。 |
| 分類 (Classification) | 正確率撞牆。決策邊界太簡單,無法有效區隔類別。 | 增加特徵工程、換非線性模型、增加樹深度。 |
| 分群 (Clustering) | 群落太粗糙。大群中明顯包含多種不同的模式。 | 增加 K 值、換更精細的距離算法。 |
筆記:遇到欠擬合,你的目標是 「增加模型的表達能力」。
五、 過擬合 (Overfitting):模型「想太多」怎麼辦?
當模型過於複雜,把數據中的雜訊也當成規律死記硬背時,就會發生過擬合。這就像是一個「死讀書」的學生。
| 任務類型 | Overfitting 的表現 (症狀) | 核心對抗策略 (緊箍咒藥方) |
|---|---|---|
| 回歸 (Regression) | 曲線極度震盪。對異常值極度敏感,死背雜訊。 | 正則化 (L1/L2)、早停 (Early Stopping)。 |
| 分類 (Classification) | 邊界破碎、扭曲。為了繞過異常點而畫出複雜邊界。 | 增加數據、正則化、限制模型複雜度。 |
| 分群 (Clustering) | 群數太多。K=N,每個點都是一圈,毫無意義。 | 降維 (PCA)、限制群數、使用密度分群。 |
筆記:遇到過擬合,你的目標是 「約束模型的行為」。
六、 本日總結:如何找到 Sweet Spot?
面對回歸任務的優化,你可以遵循以下戰略:
- 交叉驗證 (Cross-Validation):不要只相信訓練分數,用多折驗證來監控模型在未見數據上的表現。
- 正則化 (Regularization):給模型加上「緊箍咒」,防止它在複雜特徵中迷失。這也是我們在後續實戰任務中的核心武器。
- 學習曲線 (Learning Curve):觀察隨著數據量增加,誤差是否下降。如果數據量再多 R2 也不動,代表你可能欠擬合了。
下一站,我們將帶著這套「平衡理論」,進入經典的「鐵達尼號」生存預測,學習如何從資料前處理打地基,並透過正則化對抗機器學習的頭號大敵 —— 過擬合。