
—
非監督學習-分群指標-商場客戶分割為例
沒有標籤的數據,就像是一堆沒有目錄的圖書。本篇透過商場客戶資料集,帶你掌握分群指標的兩大核心:肘部法與輪廓分析,學習如何科學地從混沌中找出最具商業價值的客戶分群。
一、 資料集來源:Mall Customer Segmentation
這是一份來自 Kaggle 的開放資料集,記錄了某商場會員的基本資訊。雖然資料量不大 (200 筆),但它包含了非常具備代表性的商業維度。
資料欄位說明:
| 欄位 | 意義 | 說明 |
|---|---|---|
| CustomerID | 客戶 ID | 唯一辨識碼(分群時會剔除)。 |
| Gender / Age | 性別與年齡 | 客戶的人口統計特徵。 |
| Annual Income (k$) | 年收入 | 代表客戶的「消費口袋深度」。 |
| Spending Score | 消費分數 | 商場根據消費行為給出的評分(1-100),代表「消費意願」。 |
💡 為什麼選這兩個特徵? 在本篇中,我們鎖定 年收入 與 消費分數。這兩個維度能最直覺地劃分出客戶的商業價值(例如:有錢但不愛花錢 vs 沒錢但愛亂花錢),也是我們進行 2D 視覺化診斷的最佳對手。
一、 非監督學習的挑戰:這把尺該怎麼畫?
分群任務最難的問題不是演算法,而是:「到底該分成幾群?」
- 分太少:群體特徵模糊,行銷活動無法精準定位。
- 分太多:過於碎片化,導致運營成本過高(過擬合)。
為了找到那個 Sweet Spot,我們需要一套科學的診斷指標。
二、 指標診斷書:找出最完美的 K
我們使用 K-Means 演算法,並監控兩個關鍵指標:
1. 肘部法 (Elbow Method):看緊湊度
我們計算 WCSS (簇內誤差平方和),它代表群體內的點距離中心的距離。
- 物理意義:指標越低,代表群體內的人越「志同道合」。
- 診斷結果:如下圖 (左),在 處曲線出現了明顯的轉折(就像手肘彎曲一樣)。這代表超過 5 群後,增加群數對降低誤差的邊際效益開始遞減。
2. 輪廓分析 (Silhouette Analysis):看區分度
輪廓係數衡量的是:「我和自己人夠不夠近,且跟外人夠不夠遠?」
- 物理意義:分數越接近 1,代表群體界線越清晰。
- 診斷結果:如下圖 (右), 時的得分最高,證明了這個分法的穩健性。
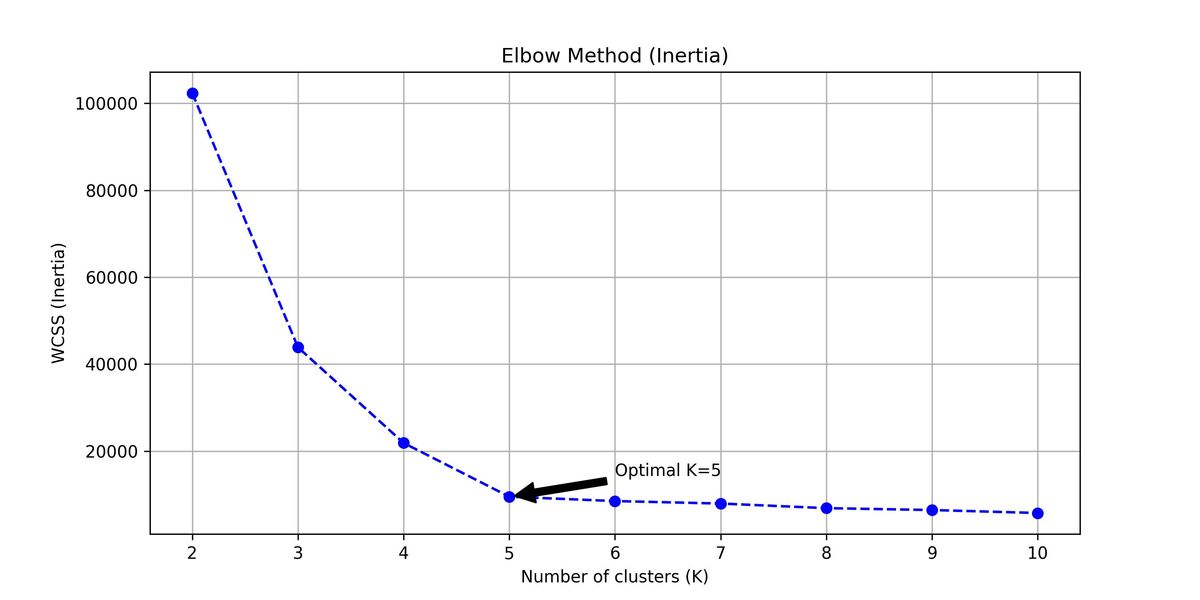
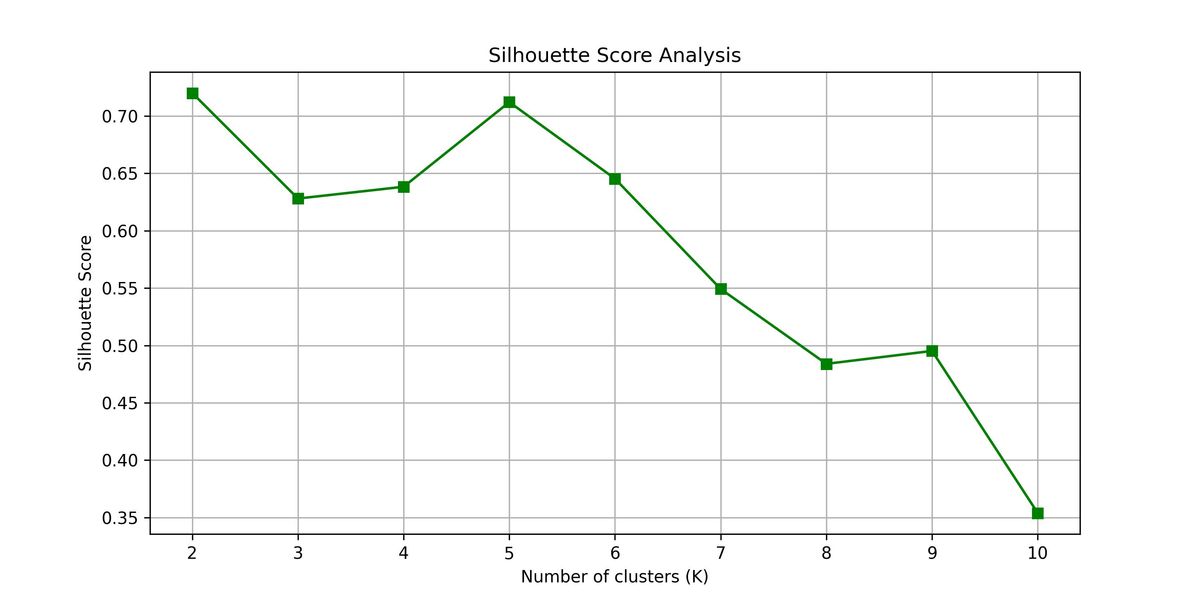
圖 A:肘部法與輪廓係數診斷圖
三、 實測對決:五大客戶畫像
當我們確定 是最佳解後,我們得到了以下極具商業價值的客戶地圖:

圖 B:最終客戶分群視覺化 (年收入 vs 消費分數)
數據背後的行動指南:我們可以做什麼?
跑出這張圖後,身為商場經理,你應該啟動以下精準行銷戰略:
- 目標族群 (Target Group, 綠色):高收入、高消費。
- 策略:頂級 VIP 服務、專屬新品發表會。這是你的利潤核心。
- 謹慎型客戶 (Careful, 紅色):高收入、低消費。
- 策略:分析其低消費原因。發送高價值產品的折扣券,或提升商場的服務質感。
- 揮霍型客戶 (Spendthrift, 青色):低收入、高消費。
- 策略:頻繁的小額促銷活動、限時閃購。
- 理性型客戶 (Sensible, 粉色):低收入、低消費。
- 策略:大宗特賣資訊、生活必需品補貨通知。
- 標竿型客戶 (Standard, 藍色):中等收入、中等消費。
- 策略:維持關係,提供一般會員權益。
四、 進階思考:當 K-Means 撞牆時
雖然 K-Means 在處理商場客戶這類「圓形分佈」的數據時表現優異,但它並非萬能。面對更複雜、帶有幾何形狀或大量雜訊的數據,它的表現會如何?
下圖展示了經典的 「半月形數據 (Moons Data)」 實驗:

圖 C:幾何形狀數據下的算法對決
- 左圖 (K-Means):慘不忍睹。它硬是用直線把月亮切成兩半,完全無視資料的幾何形狀。這是因為 K-Means 本質上是基於「歐幾里得距離」去尋找圓形中心。
- 右圖 (DBSCAN):完美! 它成功沿著月亮的彎曲形狀,將上下兩個月亮分開。
五、 總結:非監督學習的成功法則
- 無標籤不代表無規律:分群是將數據「具象化」的第一步。
- 指標是導航:不要憑感覺決定群數。Elbow 告訴你緊湊度,Silhouette 告訴你區分度。
- 商業解讀高於算法:一個好的分群結果,必須能被翻譯成「可執行的商業行動」。