
強化學習 (RL) - DQN
面對圍棋海量狀態,傳統表格已無法負擔。本文將介紹 DQN 如何結合神經網路,透過經驗回放與目標網路技術,征服複雜的遊戲世界。
WRITTEN BY

- Name
- Harry Chang
前言:當 Q 表寫不下的時候
昨天我們學了 Q-Learning,用一張表 (Q-Table) 記錄每個狀態的分數。這在簡單迷宮很有效,但如果是 圍棋 呢?圍棋的狀態數高達 ,比宇宙原子總數還多,記憶體根本存不下這張表。
為了解決這個問題,DeepMind 提出了 DQN (Deep Q-Network):既然存不下表,我們就用一個 神經網路 (Neural Network) 來「背」這張表!
案例:倒立擺 (CartPole)
我們要挑戰 OpenAI Gym 的經典遊戲:CartPole-v1。

(圖片來源:Gymnasium 官網)
- 目標:控制小車左右移動,讓桿子保持直立不倒。
- 狀態 (4 維):小車位置、小車速度、桿子角度、桿子角速度。
- 動作 (2 種):往左推、往右推。
- 獎勵:桿子每堅持一秒不倒,得 +1 分。
想像你在手掌上立起一支原子筆並試圖讓它不倒下。這是一個典型的「平衡遊戲」,對人類來說很直覺,但對 AI 來說,它必須學會如何透過微小的左右晃動來抵消桿子的重力。
為了讓大家看懂 DQN 是如何「迭代」變強的,我們將剛才的法寶帶入 CartPole (平衡桿子) 的案例中:
這個流程展示了 AI 的進化過程:
- 觀察與決策:AI 看到桿子的角度後,由「學生大腦」決定推動方向。
- 累積經驗:不論結果好壞,AI 都會把這段經歷(日記)存進 回放庫。
- 深度學習:AI 每天從回放庫隨機抽出 64 篇日記來「複習」,這讓它能從過去的失敗中學會:「當桿子斜 5 度時,一定要及時回推」。
- 穩定傳承:學生學到新技巧後,會定期同步給「老師大腦」,確保整個訓練過程穩紮穩打。
- 同步機制 (更新):每隔一段時間,學生會將學到的參數「拷貝」給老師,維持教學品質。
DQN 的三大法寶
要讓神經網路學會玩遊戲並不容易,DQN 用了三個關鍵技術來穩定訓練:
Q-Network (用 AI 取代查表)
- 以前:查表
Q_Table[state][action]。 - 現在:問 AI
model(state)-> 直接輸出所有動作的分數。
Experience Replay (經驗回放)
把玩過的經驗 全部丟進一個 「回憶庫」 (Replay Buffer)。
這是 RL 的「日記格式」,記錄了每一步發生了什麼:
- S (State):我看到了什麼?(例如:桿子斜向右邊)。
- A (Action):我做了什麼?(例如:向右推小車)。
- R (Reward):結果好不好?(例如:桿子沒倒,+1 分)。
- S' (Next State):做完動作後,變成怎樣?(例如:桿子回正了)。
意義:我們把這些「日記」存起來,訓練時隨機拿出來複習,這樣 AI 才不會只記得剛發生的事(打亂時間相關性,學得更全面)。
Target Network (固定目標)
為了避免訓練時「左腳踩右腳」的不穩定,DQN 準備了兩個網路:
- 學生網路:負責玩遊戲,隨時更新參數。
- 老師網路:負責算分數,參數固定一段時間才從學生那裡複製過來。
實戰:CartPole 訓練成果
在執行程式後,你會在終端機看到類似這樣的日誌,並且最後得到一張分數變化圖。
訓練日誌解讀 (Log Explanation)
Episode 191/200, Score: 98, Epsilon: 0.38
Episode 192/200, Score: 23, Epsilon: 0.38
Episode 193/200, Score: 126, Epsilon: 0.38
Episode 194/200, Score: 19, Epsilon: 0.38
Episode 195/200, Score: 25, Epsilon: 0.38
Episode 196/200, Score: 138, Epsilon: 0.37
Episode 197/200, Score: 98, Epsilon: 0.37
Episode 198/200, Score: 25, Epsilon: 0.37
Episode 199/200, Score: 119, Epsilon: 0.37
Episode 200/200, Score: 130, Epsilon: 0.37
- Episode 191 ~ 200:這是 200 回合訓練即將結束前的最後衝刺。
- Score (98 -> 19 -> 130):你會發現分數劇烈震盪。
- 例如 193 回合 拿到了 126 分的高分,但 194 回合 卻突然掉到 19 分。
- 原因:這就是 DQN 的特性,AI 還在微調參數,有時候學到新招式反而會打亂舊有的平衡感,這需要更多時間來穩定。
- Epsilon (0.38 -> 0.37):你會看到探索率在 196 回合稍微降了一點點。
- 這代表 AI 正在緩慢地減少「亂試」的頻率,變得越來越相信自己學到的「平衡大法」。
結果圖解說
執行程式後得到的分數變化圖如下:
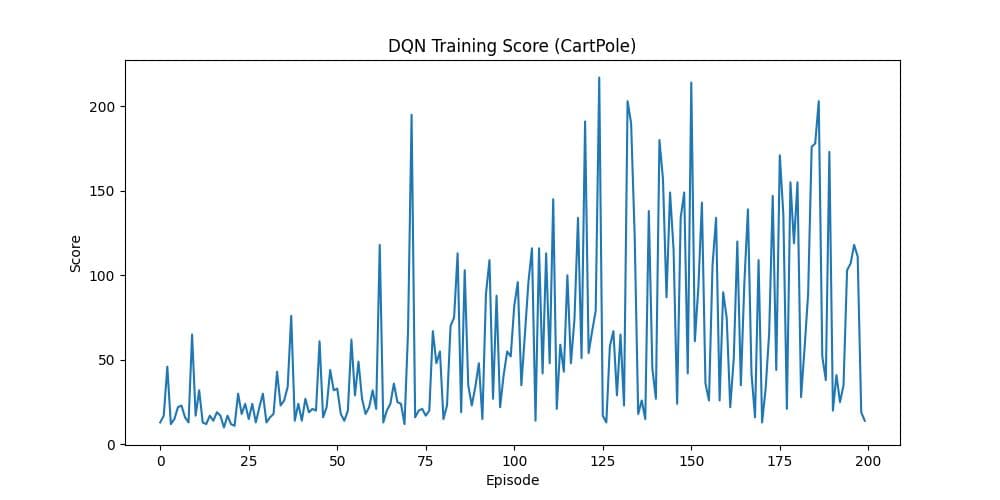
- X 軸 (Episode):訓練的回合數 (玩了幾次遊戲)。
- Y 軸 (Score):堅持的時間 (秒)。
- 趨勢解讀:
- 0~50 回合:分數很低 (10~20 分),Agent 還在隨機亂試 (Epsilon 很高)。
- 50~150 回合:分數開始劇烈震盪。這是 DQN 的特性,它正在嘗試不同的策略,有時候會突然開竅 (飆高),有時候又會忘記 (跌低)。
- 150+ 回合:分數忽高忽低,但分數逐漸在平均分之上 (>100),代表 Agent 已經掌握了平衡的技巧。
總結
DQN 的成功在於它解決了「記憶體不足」與「訓練不穩定」的問題,開啟了深度強化學習的大門。
下一關我們將介紹 Policy Gradient (策略梯度),這是現代 LLM (如 ChatGPT) 訓練中不可或缺的關鍵技術!