
強化學習 (RL) - Policy Gradient
DQN 雖然強大,但無法處理連續動作且決策過於死板。本文將介紹 Policy Gradient (策略梯度),這是一種直接學習動作機率的方法,也是現代 LLM (如 ChatGPT) 訓練的核心演算法。
前言:DQN 的遺憾
前兩天我們學的 Q-Learning 和 DQN 都是 Value-Based (基於價值) 的方法:
- 核心:算出每個動作的「分數」(Q-Value)。
- 決策:選分數最高的那個動作。
但這在現實世界中有幾個痛點:
- 無法處理連續動作:如果動作不是「左、右」,而是「方向盤轉 30.5 度」,DQN 就掛了(因為你不能窮舉所有角度來算分數)。
- 無法學到隨機策略:有些遊戲(如剪刀石頭布)最好的策略是「隨機出」,但 DQN 永遠只會選分數最高的那個,太死板且容易被對手預測。
今天我們要介紹 Policy Gradient (策略梯度),它是 Policy-Based (基於策略) 的方法。
- 核心:不需算分數,直接學一個神經網路
Policy(State)->Action Probability。 - 直覺:看到這個畫面,我有 70% 機率往左,30% 機率往右。
案例:登陸月球 (LunarLander)
我們要挑戰比 CartPole 更難的遊戲:LunarLander-v3。
(圖片來源:Gymnasium 官網)
目標:控制登月小艇,安全降落在兩個旗幟中間。
狀態 (8 維):
- X 座標 (水平位置)
- Y 座標 (垂直高度)
- X 速度 (水平飛多快)
- Y 速度 (下降多快)
- 角度 (小艇歪了嗎)
- 角速度 (轉動多快)
- 左腳觸地 (是/否)
- 右腳觸地 (是/否)
動作 (4 種):
- 什麼都不做 (Do nothing)
- 主引擎噴射 (Fire main engine) - 往上推
- 左引擎噴射 (Fire left engine) - 往右推
- 右引擎噴射 (Fire right engine) - 往左推
獎勵:安全著陸 +100,墜毀 -100,噴射引擎會扣一點分 (節省燃料)。
Policy Network 訓練架構圖
核心概念:REINFORCE 演算法 這是最基礎、最經典的 Policy Gradient 演算法。它的邏輯非常符合人類的直覺:「贏了就多做,輸了就少做」。
運作流程
- 玩一整場 (Rollout):Agent 根據目前的策略玩完一整局遊戲,記錄下所有的
(State, Action, Reward)。 - 算總帳 (Return):計算這場遊戲總共拿了多少分 ()。
- 獎懲分明 (Update):
- 贏了:增加這場遊戲中「所有做過的動作」出現的機率。
- 輸了:減少這些動作出現的機率。
Policy Network 訓練架構圖
與 DQN 相比,Policy Gradient 的訓練流程更為精簡,強調的是「玩完一局後算總帳」。
與 DQN 的關鍵差異:
- 無回放庫 (No Buffer):通常是走完一整局後直接學習,不需要存儲歷史日記。
- 機率抽樣:動作是「抽樣」出來的,這讓 AI 即使在相同情況下也可能嘗試不同動作。
- 全局優化:它看的是這場遊戲的「總回報 G」,而非單步的預測。
💡 實戰舉例:小艇怎麼學會降落?
- 看到畫面 (State):小艇現在歪了 (角度 30 度),且下降速度很快。
- 神經網路 (Policy Net):算出每個動作的建議機率(例如:主引擎 60%、右引擎 25%、什麼都不做 10%、左引擎 5%)。
- 隨機抽樣 (Action):根據機率丟骰子。雖然主引擎機率最高,但 AI 這次隨機抽到了「右引擎」。
- 環境回饋 (Environment):執行「右引擎」後,記錄當下的狀態、做的動作,以及獲得的單步回饋(可能是扣燃料分)。
- 玩完一局算總帳 (Return):不斷重複直到小艇降落或墜毀,最終結算這整場遊戲的總分數 (例如這局最終墜毀了,拿到 -150 分)。
- 策略更新 (Update):根據總分來檢討。因為這局是負分,系統會懲罰這局做過的所有決策,包含剛才「在歪 30 度時噴右引擎」的這個動作。
- 更新網路參數 (Backprop):微調神經網路權重。下次遇到同樣歪 30 度的畫面時,噴「右引擎」的機率就會被調低(例如從 25% 降到 15%)。
實戰:登陸月球 (LunarLander) 訓練成果
執行程式後,終端機會顯示各回合的訓練日誌:
Episode 420/500, Score: 8.83
Episode 440/500, Score: 37.70
Episode 450/500, Score: -107.04
Episode 480/500, Score: -7.46
Episode 500/500, Score: 34.58
將 500 回合的分數繪製成圖表如下:
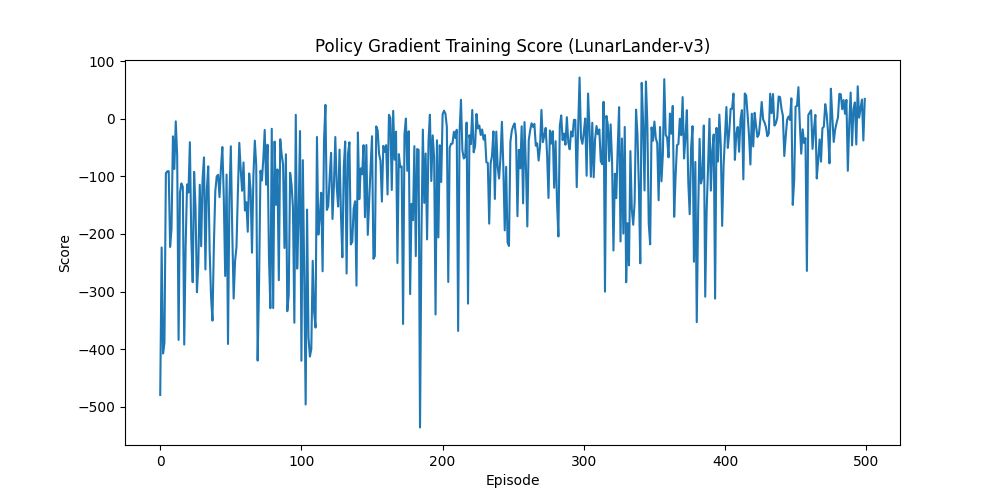
(Policy Gradient - LunarLander 訓練成效圖)
- 圖表背景:這張圖表呈現的是 Policy Gradient 在 LunarLander-v3 (登陸月球) 遊戲上的真實訓練結果。
- X 軸 (Episode):訓練的回合數 (0 ~ 500 回合)。
- Y 軸 (Score):單局獲得的總分 (官方設定滿分約為 200~250 分)。
- 趨勢解讀:
- 前期 (0~200 回合):分數非常慘烈,幾乎都在 -100 到 -400 之間來回震盪,代表小艇只會瘋狂墜毀與浪費燃料。
- 中期 (200~350 回合):平均分數慢慢往 0 分靠近,偶爾能稍微突破 0 分,代表小艇開始學會「平穩下降」不亂扣分。
- 後期 (350~500 回合):從終端機日誌可以發現,分數終於開始出現穩定的正分(如 37.70, 45.67 分),代表小艇已經偶爾能成功著陸。但同時也能看出圖表的上下震盪依舊非常劇烈。
- 關鍵觀察 (PG 的致命傷): 仔細看圖表後段以及日誌,明明第 440 回合拿了不錯的正分 (37.70),第 450 回合卻又突然暴跌墜毀 (-107.04 分)。 這完美展現了基礎 Policy Gradient (REINFORCE) 的最大痛點 —— 高變異性 (High Variance)。因為它是靠「機率抽樣」來決定動作,就算正確策略的機率已經提高了,只要運氣不好抽到「手滑」的錯誤動作(例如快降落時突然亂噴引擎),就會導致分數瞬間崩盤,訓練極度不穩定。這也是為什麼當今的 LLM 訓練(如 ChatGPT)或複雜機器人控制,必須改用 PPO 演算法的原因!
總結
Policy Gradient 的成功在於它跳出了「算分數」的框架,直接去優化「行為」。這讓它在處理連續動作、隨機策略以及複雜的語言生成 (LLM) 上展現出無與倫比的優勢。
下一關我們將介紹當今 AI 界真正的霸主、ChatGPT 背後的核心大腦 —— PPO (Proximal Policy Optimization) 演算法,並用幾行程式碼秒殺今天的登陸月球任務,徹底終結 Policy Gradient 的不穩定!