
強化學習 (RL) - PPO
徹底終結 Policy Gradient 的不穩定!本篇將介紹 OpenAI 提出的 PPO 演算法,它是當代強化學習的霸主,更是訓練 ChatGPT (RLHF) 的核心基石。我們將使用 Stable-Baselines3 快速實作。
WRITTEN BY

- Name
- Harry Chang
前言:PG 的痛點與 PPO 的誕生
在昨天的文章中,我們見識到了 Policy Gradient (PG) 的威力與致命傷:高變異性 (High Variance)。因為它全靠機率抽樣,只要運氣不好抽錯動作,辛苦建立的策略就會瞬間崩盤,導致分數像心電圖一樣劇烈震盪(例如上一秒還有 37 分,下一秒直接暴跌到 -100 分)。
為了解決這個問題,OpenAI 在 2017 年提出了 PPO (Proximal Policy Optimization,近端策略優化)。 PPO 出現後,幾乎統治了強化學習領域。它不僅是控制機器人、玩遊戲的首選,更是訓練 ChatGPT (RLHF, 透過人類回饋增強學習) 最核心的大腦演算法!
今天,我們就來揭開這套「霸主級」演算法的面紗。
案例:登陸月球 (LunarLander)
我們同樣挑戰:LunarLander-v3。
(圖片來源:Gymnasium 官網)
PPO 訓練架構圖
PPO 為什麼這麼穩?(兩大秘密武器)
PPO 其實是融合了 DQN 的「價值判斷」與 PG 的「策略機率」,並加上了「安全煞車系統」。
1. Actor-Critic (雙網路架構)
PPO 通常建立在 Actor-Critic 架構上:
- Actor (演員):也就是原本的 Policy Net,負責「看畫面、決定動作機率」。
- Critic (影評人):類似 DQN 的 Value Net,負責「看畫面、預測這局最終能拿多少分」。
運作方式:Actor 每做一個動作,Critic 就會根據結果給出評價(這叫 Advantage 優勢函數)。如果 Critic 覺得這個動作「比預期中更好」,Actor 就會增加該動作的機率;反之則減少。這比 PG 只能「玩完一局盲目檢討」要精準得多!
2. Clip 截斷機制 (安全煞車系統)
這是 PPO 的靈魂!在 PG 中,如果某個動作得了超高分,神經網路會過度興奮,把該動作的機率一次調高太多,導致「走火入魔」忘記其他技巧。 PPO 加入了 Clip (截斷) 數學公式,它強制規定:
「無論這個動作有多好,每次更新策略的幅度,最多只能在舊策略的 0.8 到 1.2 倍之間(變動不超過 20%)。」
這就像學騎腳踏車,PPO 不允許你一次把重心偏移 90 度,而是規定每次只能微調。這種「穩紮穩打、步步為營」的機制,徹底消除了 PG 突然崩盤的風險。
** 實戰舉例:PPO 雙網路怎麼合作降落?**
- 環境狀態 (State):小艇現在歪了 30 度,正在快速往下掉。
- Actor (演員):看看畫面,給出機率:「我覺得這時候噴『右引擎』的勝率最高 (60%)」。
- Critic (影評人):看看畫面,給出預測:「以我目前的經驗,在歪 30 度的情況下,這局最後大概只能拿 50 分」。
- 執行動作 (Action):根據 Actor 的機率丟骰子,執行了噴「右引擎」。
- 環境回饋 (Reward):噴了引擎後小艇完美回正了!這步拿到了加分,而且進入了一個更安全的新狀態。
- 計算優勢 (Advantage):系統結算後發現,這一連串下來最後拿了 80 分。Critic 一看:「咦?實際拿了 80 分,比我當初預期的 50 分還高了 +30 分 (這就是 Advantage 優勢)!代表 Actor 剛才噴右引擎這步是一步好棋!」
- Clip 截斷 (安全煞車):因為表現比預期好,系統準備大幅提高「噴右引擎」的機率(原本可能想一口氣暴力調到 99%)。但 Clip 機制立刻介入攔截:「慢著!不管多成功,一次最多只能變動 20%,調到 72% 就好。」
結果:Actor 乖乖把機率調高到 72%,Critic 也修正了自己的預測眼光。既學到了好招,又不會因為太興奮而走火入魔忘記其他技巧!
實戰:Stable-Baselines3
PPO 底層的數學公式與優勢函數 (GAE) 手刻起來非常複雜且容易有 Bug。因此在業界,我們通常直接使用最強的強化學習套件:Stable-Baselines3 (SB3)。
只要短短幾行程式碼,就能載入 PPO 模型並開始訓練登陸月球 (LunarLander)!
import gymnasium as gym
from stable_baselines3 import PPO
# 1. 建立 LunarLander 環境
env = gym.make("LunarLander-v3")
# 2. 建立 PPO 模型 (MlpPolicy 代表使用全連接層神經網路)
model = PPO("MlpPolicy", env, verbose=1)
# 3. 開始訓練 (訓練 100,000 步)
model.learn(total_timesteps=100000)
# 4. 儲存模型
model.save("ppo_lunarlander")
就是這麼簡單!SB3 把所有複雜的 Actor-Critic 網路建構、Clip 計算都封裝好了,讓開發者能專注在訓練與應用上。
訓練日誌解析:看懂 PPO 的專業指標
執行訓練後,你會在終端機看到類似下方這樣充滿專業名詞的日誌:
------------------------------------------
| rollout/ | |
| ep_len_mean | 601 |
| ep_rew_mean | 2.64 |
| time/ | |
| total_timesteps | 100352 |
| train/ | |
| clip_fraction | 0.0261 |
| explained_variance | 0.721 |
| learning_rate | 0.0003 |
| loss | 54.9 |
| value_loss | 55.3 |
------------------------------------------
身為專業的 AI 工程師,你需要看懂以下幾個關鍵指標:
- ep_rew_mean (平均回報):最直觀的分數。這裡看到訓練到 10 萬步時,平均分數已經從負數慢慢爬回正數(2.64分),代表小艇開始掌握初步的降落訣竅。
- clip_fraction:有多少比例的更新觸發了「Clip 截斷」機制。這裡的
0.0261,代表大約有 2.6% 的策略更新企圖跨大步,但被 PPO 的安全煞車成功攔截了。 - explained_variance:Critic (影評人) 預測分數的準確度。這個值越接近
1越好!這邊是0.721,代表 Critic 已經能相當準確地評估局勢,從而給予 Actor 正確的指導方向。
成果對比:PG vs PPO 穩定度對決
最後,我們把訓練分數畫成圖表。藍線是原始的單局分數,紅線則是平滑後的趨勢線:
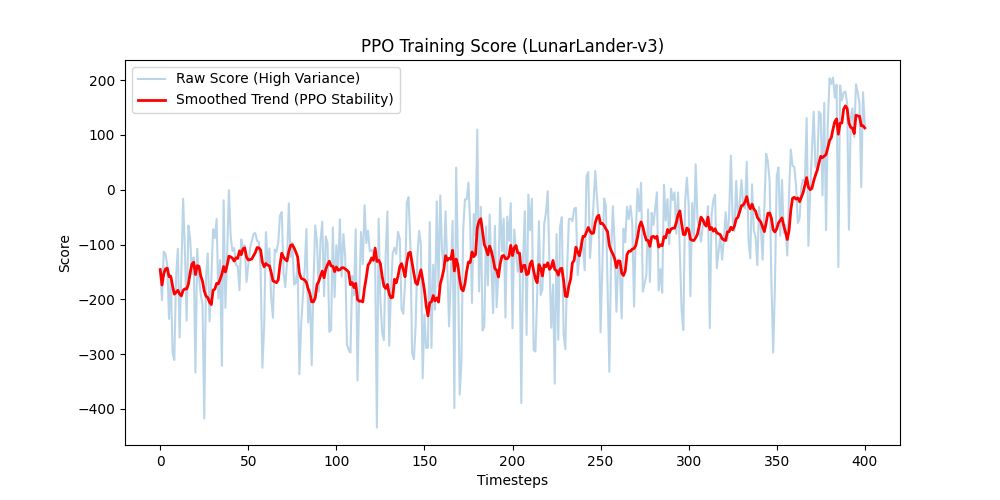
(PPO 訓練成效圖:紅色為平滑趨勢線)
- 真正的滿分:LunarLander 官方設定的「完美解決」分數大約落在 200 分左右。
- 終極穩定度 (紅線):回想昨天 PG 那個動不動就從正分暴跌回 -400 分的「瘋狂心電圖」。看看 PPO 的紅色趨勢線,它是一條極度平滑、穩穩往上爬升,最終穩穩突破 150 分邁向滿分線的完美斜線!
- 這就是 PPO 的價值:它確保神經網路「只要學會了降落技巧,就不會輕易忘記」。
總結
PPO 透過 Actor-Critic 雙網路 提升評估精準度,再透過 Clip 截斷機制 確保步伐穩定,完美解決了傳統 Policy Gradient 的高變異性問題。這套「穩紮穩打」的哲學,讓它成為了目前訓練複雜 AI (包含 ChatGPT) 最可靠的選擇。
下一關,我們終於要踏入一個全新的領域:XAI (可解釋 AI) — 既然 AI 這麼強大,我們該如何看穿它的「黑盒子」,知道它到底為什麼會這樣判斷?這是邁向資深工程師的必修課!