Ai相關
非監督學習-推薦系統實戰-以MovieLens 100k為例
為什麼 Netflix 比你還了解你的電影品味?本篇揭開推薦系統神祕的面紗,學習如何利用 SVD (奇異值分解) 將巨大的評分矩陣進行分解,從而挖掘出隱藏的「電影基因」,實現精準的個人化推薦。
非監督學習-PCA 降維-以乳腺癌診斷數據為例
面對 30 個維度的數據,人類的視覺已經失靈。本篇透過乳腺癌資料集,展示如何利用 PCA (主成分分析) 進行數據瘦身,將高維度的訊息「壓縮」成 2 維的可視化地圖,並學會讀懂這張地圖背後的變異真相。
非監督學習-關聯規則-以尿布與啤酒為例
為什麼尿布和啤酒會被擺在一起?這不是巧合,而是數據的旨意。本篇深入解析關聯規則的三大支柱:支持度、置信度與提升度,帶你從購籃數據中挖掘出反直覺的商業金礦。
非監督學習-分群指標-商場客戶分割為例
沒有標籤的數據,就像是一堆沒有目錄的圖書。本篇透過商場客戶資料集,帶你掌握分群指標的兩大核心:肘部法與輪廓分析,學習如何科學地從混沌中找出最具商業價值的客戶分群。
模型優化策略-合成正弦波數據為例
為什麼模型在訓練時表現完美,上線後卻一塌糊塗?本篇透過經典的「正則波」實驗,帶你直觀理解偏差 (Bias) 與方差 (Variance) 的博弈,學會如何抓出「只會死背」的過擬合模型。
監督學習-回歸模型評估-加州房價預測為例
離開了「是非題」的分類世界,今天我們要進入「填空題」的回歸領域。透過加州房價預測,學習如何用 RMSE 與 R-squared 來衡量模型的精準度,並學會看穿殘差圖背後的真相。
監督學習-分類模型-資料預處理&模型優化-鐵達尼號數據為例
在解決了「如何衡量模型」後,今天我們要進入真實世界的戰場。透過鐵達尼號資料集,學習如何從髒亂的原始數據開始,打好資料前處理的地基,並透過正則化與交叉驗證,打造出強健的分類引擎。
監督學習-分類模型評估-乳腺癌診斷數據為例
分類任務不只是選擇演算法。本篇透過乳腺癌診斷資料集,深入解析為什麼 Accuracy 會騙人、如何利用 L1/L2 正則化對抗過擬合,並透過 GridSearchCV 自動化尋找最佳模型參數。
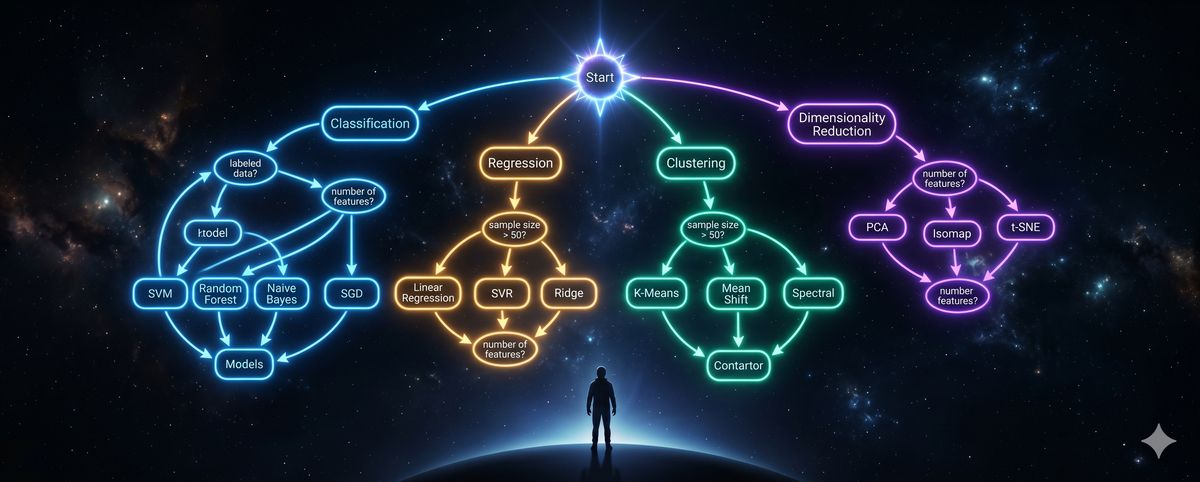
ML基礎全景指南:從 Scikit-Learn 演算法地圖到四大實戰任務
這是一份專為初學者設計的機器學習全景地圖。我們將從 AI/ML/DL 的核心架構出發,跟著 Scikit-Learn 官方地圖,一站式走完分類、回歸、分群與降維這四大核心實戰任務。